
写在前面
今年 4 月到 5 月期间,我花了将近一个月的时间,完整走了一遍电商用户行为分析的全链路。这个项目源自我对精细化运营的好奇——在电商行业里,"所有人发同样的优惠券"这种粗放式营销早已被诟病多年,但真正落到数据层面,如何用科学的方法识别高价值用户、预警流失风险、制定差异化策略?带着这个问题,我基于 UCI Machine Learning Repository 提供的英国在线零售商真实交易数据,搭建了一套从数据清洗、KPI 核算、RFM 价值分群到可视化看板与运营策略输出的完整分析体系。
这篇文章会尽可能详细地记录整个项目的思考过程、技术实现和最终产出的业务洞察。如果你也在学习用户增长或数据分析,希望这篇实战记录能给你一些参考。
一、项目概述与业务价值
1.1 为什么做这个项目
电商运营的核心矛盾永远是有限的营销预算与无限的用户需求之间的错配。传统的"一刀切"营销方式——比如给全站用户发同一张满减券——不仅 ROI 低下,还可能打扰到低价值用户,甚至引发退订。
用户分层是精细化营销的基础。通过数据驱动的方式将用户划分为不同价值层级后,可以实现:
- 精准投放资源:将营销预算集中在高价值用户群体,提升 ROI
- 降低流失率:及时识别流失风险用户,通过召回策略减少用户流失
- 提升复购率:针对有消费潜力但近期未下单的用户,设计激活活动
- 优化产品策略:根据高价值用户的品类偏好,调整库存结构与上新节奏
1.2 核心能力覆盖
本项目最终实现了三大核心能力:
- 数据清洗与指标核算:搭建用户消费核心 KPI 报表,覆盖活跃度、客单价、复购频次等维度,可支持运营活动效果的日常追踪
- RFM 模型 + 五分位法:划分 8 类用户层级,精准识别高价值用户与流失风险群体,输出分群运营策略建议
- 多维度业务看板:基于 Python 输出消费趋势时序图、用户价值矩阵,可快速完成活动复盘与数据呈现
二、数据集说明与数据特点
2.1 数据来源
本项目使用了三套同源的 UCI Online Retail 数据集,分别来自不同渠道,便于对比验证分析结果的稳定性:
| 数据集 | 来源 | 时间范围 | 原始记录数 | 有效记录数 | 用户数 |
|---|---|---|---|---|---|
| Online Retail.xlsx | UCI 官方 | 2010-12 ~ 2011-12 | 541,909 | 391,867 | 4,318 |
| OnlineRetail.csv | 阿里云天池 | 2010-12 ~ 2011-12 | 541,909 | 391,867 | 4,318 |
| online_retail_II.csv | Kaggle | 2009-12 ~ 2011-12 | 1,067,371 | 777,859 | 5,838 |
2.2 字段说明
| 字段 | 含义 | 示例 |
|---|---|---|
InvoiceNo |
订单号(以 C 开头表示取消/退货) | 536365 |
StockCode |
商品编码 | 85123A |
Description |
商品描述 | WHITE HANGING HEART T-LIGHT HOLDER |
Quantity |
购买数量(负数表示退货) | 6 |
InvoiceDate |
订单日期时间 | 2010-12-01 08:26:00 |
UnitPrice |
商品单价(英镑) | 2.55 |
CustomerID |
客户唯一标识 | 17850 |
Country |
客户所在国家 | United Kingdom |
2.3 数据特点与挑战
该零售商主营礼品与家居用品,客户以批发商和小型企业为主。数据中存在几个显著的清洗挑战:
- 大量退货记录:
Quantity < 0的退货订单需要识别并处理 - CustomerID 缺失:约 22% 的记录缺少用户标识,无法归属到具体用户
- 极端异常值:单价与数量分布极不均匀,存在明显的极端异常值,需要合理的过滤策略
- 多数据集适配:三套数据字段命名和格式略有差异,需要统一的加载和标准化流程
三、技术架构与项目结构
3.1 整体架构
整个分析流程分为四层:
数据层 (Datasets)
├── UCI XLSX
├── 阿里云 CSV
└── Kaggle CSV (II代)
↓
数据处理层 (ETL & Clean)
├── 加载 → 去重 → 缺失值处理 → 异常值过滤 → 字段标准化
↓
分析层
├── KPI 指标核算(月度销售额、客单价、复购率、品类偏好)
├── RFM 价值分群(Recency/Frequency/Monetary 打分 + 五分位法)
└── 可视化看板(消费趋势图、RFM矩阵图、三维散点图、活跃度分析)
↓
输出层 (Results & Reports)
├── 综合运营报表.xlsx
├── kpi_report.xlsx
├── rfm_report.xlsx
└── charts/ (4张PNG看板图)
3.2 技术栈
| 类别 | 工具/库 | 用途 |
|---|---|---|
| 编程语言 | Python 3.x | 全链路数据处理与分析 |
| 数据处理 | pandas, numpy | 数据清洗、聚合、统计计算 |
| 可视化 | matplotlib, seaborn | 静态图表与看板生成 |
| 报表输出 | openpyxl | Excel 多 Sheet 报表 |
| 版本控制 | Git | 代码版本管理 |
3.3 项目目录结构
.
├── src/
│ ├── generate_data.py # 模拟数据生成(用于无真实数据时的演示)
│ ├── load_uci_data.py # 真实数据集加载与字段适配
│ ├── data_cleaning.py # 数据清洗(去重、缺失值、异常值、退货过滤)
│ ├── kpi_analysis.py # 用户消费核心 KPI 核算
│ ├── rfm_analysis.py # RFM 模型 + 五分位法八分群
│ └── visualization.py # 多维度可视化看板生成
├── datasets/ # 原始数据集(Git 忽略,需自行下载)
├── results/ # 分析结果输出(Git 忽略,运行后生成)
├── docs/ # 文档与配图
├── main.py # 单数据集分析入口
├── run_all_datasets.py # 三数据集批量分析入口
├── requirements.txt
└── README.md
四、分析全流程详解
4.1 数据清洗:脏数据是分析的天敌
原始数据存在大量的脏数据,必须经过严格的清洗流程才能保证后续分析的准确性。以下是 Online Retail II 数据集的清洗全过程:
| 步骤 | 处理方式 | 处理数量 |
|---|---|---|
| 加载原始数据 | 读取 CSV,解析日期字段 | 1,067,371 条 |
| 删除 CustomerID 缺失 | CustomerID 为空的记录无法识别用户,直接删除 |
-243,007 条 |
| 删除取消/退货订单 | InvoiceNo 以 C 开头或 Quantity <= 0 |
-18,815 条 |
| 过滤极端异常值 | 使用 IQR 法过滤单价与数量的极端异常 | -1,594 条 |
| 标准化字段 | 重命名列、计算 item_amount = Quantity * UnitPrice |
- |
| 最终有效数据 | - | 777,859 条 |
核心清洗代码:
def clean_data(df):
# 删除 CustomerID 缺失的记录
df = df.dropna(subset=['CustomerID'])
# 删除取消订单(InvoiceNo 以 C 开头)和退货(Quantity <= 0)
df = df[~df['InvoiceNo'].astype(str).str.startswith('C')]
df = df[df['Quantity'] > 0]
# 使用 IQR 法过滤极端异常值
for col in ['UnitPrice', 'Quantity']:
Q1 = df[col].quantile(0.25)
Q3 = df[col].quantile(0.75)
IQR = Q3 - Q1
lower = Q1 - 3 * IQR
upper = Q3 + 3 * IQR
df = df[(df[col] >= lower) & (df[col] <= upper)]
# 计算单品金额
df['item_amount'] = df['Quantity'] * df['UnitPrice']
return df
这里我采用的是 IQR 法(四分位距法) 过滤异常值,而不是简单的 3σ 原则。原因是电商数据的单价和数量分布通常是极度右偏的,3σ 原则在这种分布下会过滤掉过多正常数据。IQR 法对偏态分布更加稳健。
4.2 KPI 指标体系:建立运营数据基准
清洗后的数据首先用于构建用户消费核心 KPI 报表,覆盖以下维度:
月度销售趋势
monthly_kpi = df.groupby('order_month').agg(
total_sales=('item_amount', 'sum'),
total_orders=('order_id', 'nunique'),
total_users=('user_id', 'nunique'),
avg_order_value=('item_amount', 'mean')
).reset_index()
分析期内月度销售额呈现明显波动,其中 2011 年 11 月达到峰值(受黑五/圣诞季促销影响),2011 年 12 月因数据截断仅包含 9 天数据。
用户活跃度分层
| 活跃度等级 | 定义 | 用户数(II代) | 占比 |
|---|---|---|---|
| 高活跃 | 购买频次 >= 中位数 + 1个标准差 | 1,105 | 18.9% |
| 中活跃 | 购买频次在 [中位数, 中位数+标准差) | 1,299 | 22.3% |
| 低活跃 | 购买频次 < 中位数 | 2,334 | 40.0% |
| 沉睡用户 | 最后购买日期距今 > 90天 | 1,730 | 29.6% |
复购率与客单价
total_users = df['user_id'].nunique()
repurchase_users = df.groupby('user_id')['order_id'].nunique()
repurchase_rate = (repurchase_users > 1).sum() / total_users
avg_order_value = df.groupby('order_id')['item_amount'].sum().mean()
- 整体复购率:72.35% —— 说明产品质量与用户满意度较高
- 整体客单价:£413 —— 批发商为主的客户结构导致客单价偏高
品类偏好分析
数据集中商品数量庞大(约 3,800+ 种),通过关键词提取将商品归为 7 大品类:
| 品类 | 描述 | 核心商品举例 |
|---|---|---|
| 家居装饰 | 蜡烛、相框、挂件 | CANDLE, FRAME, HANGING |
| 厨房用品 | 餐具、烘焙工具 | CAKE, MUG, LUNCH BOX |
| 节日礼品 | 圣诞、情人节主题 | CHRISTMAS, VALENTINE |
| 文具手账 | 笔记本、便签 | NOTEBOOK, PAPER, PEN |
| 园艺户外 | 花盆、园艺工具 | GARDEN, PLANTER |
| 儿童玩具 | 积木、玩偶 | DOLL, TOY, BLOCKS |
| 其他 | 无法归类的长尾商品 | BAG, CLOCK, LAMP 等 |
4.3 RFM 模型原理与实现
4.3.1 指标计算
RFM 模型是客户关系管理领域最经典的用户价值分析模型。三个维度的计算逻辑如下:
def calculate_rfm(df, analysis_date=None):
if analysis_date is None:
analysis_date = df['order_date'].max() + timedelta(days=1)
rfm = df.groupby('user_id').agg(
last_purchase_date=('order_date', 'max'),
frequency=('order_id', 'nunique'),
monetary=('item_amount', 'sum')
).reset_index()
rfm['recency'] = (analysis_date - rfm['last_purchase_date']).dt.days
return rfm[['user_id', 'recency', 'frequency', 'monetary']]
4.3.2 五分位法打分
对每个维度的指标值按五分位划分为 1~5 分。这里有一个关键细节:Recency 越小越好,所以打分方向与 Frequency/Monetary 相反。
def rfm_score(x, col, quintiles):
if col == 'recency':
# Recency 越小越好,反向打分
if x <= quintiles[col][0.2]: return 5
elif x <= quintiles[col][0.4]: return 4
elif x <= quintiles[col][0.6]: return 3
elif x <= quintiles[col][0.8]: return 2
else: return 1
else:
# Frequency 和 Monetary 越大越好
if x <= quintiles[col][0.2]: return 1
elif x <= quintiles[col][0.4]: return 2
elif x <= quintiles[col][0.6]: return 3
elif x <= quintiles[col][0.8]: return 4
else: return 5
4.3.3 八分群逻辑
将 R、F、M 的得分分别与各自的中位数(3分)比较,得到高低两个层级,组合成 8 类用户:
def classify_rfm(row):
r, f, m = row['R_score'] >= 3, row['F_score'] >= 3, row['M_score'] >= 3
if r and f and m: return '重要价值用户'
if r and not f and m: return '重要发展用户'
if not r and f and m: return '重要保持用户'
if not r and not f and m: return '重要挽留用户'
if r and f and not m: return '一般价值用户'
if r and not f and not m: return '一般发展用户'
if not r and f and not m: return '一般保持用户'
return '流失风险用户'
| 用户层级 | R | F | M | 业务含义 |
|---|---|---|---|---|
| 重要价值用户 | 高 | 高 | 高 | 核心 VIP,贡献最多营收 |
| 重要发展用户 | 高 | 低 | 高 | 有消费力但频次低,需提升粘性 |
| 重要保持用户 | 低 | 高 | 高 | 曾经是 VIP,需召回激活 |
| 重要挽留用户 | 低 | 低 | 高 | 高价值但即将流失,需紧急挽留 |
| 一般价值用户 | 高 | 高 | 低 | 活跃且忠诚,但消费力有限 |
| 一般发展用户 | 高 | 低 | 低 | 新用户或低频用户,需培养习惯 |
| 一般保持用户 | 低 | 高 | 低 | 曾经活跃但近期沉默 |
| 流失风险用户 | 低 | 低 | 低 | 即将流失或已流失,需评估是否召回 |
五、核心分析结果
以下结果基于 Online Retail II(第二代)数据集(2009-12 ~ 2011-12,777,859 条有效记录)。
5.1 总体概览
| 指标 | 数值 |
|---|---|
| 数据时间范围 | 2009-12-01 ~ 2011-12-09 |
| 清洗后有效记录 | 777,859 条 |
| 覆盖订单数 | 36,580 笔 |
| 覆盖用户数 | 5,838 人 |
| 总销售额 | £16,369,951 |
| 整体复购率 | 72.35% |
| 整体客单价 | £413 |
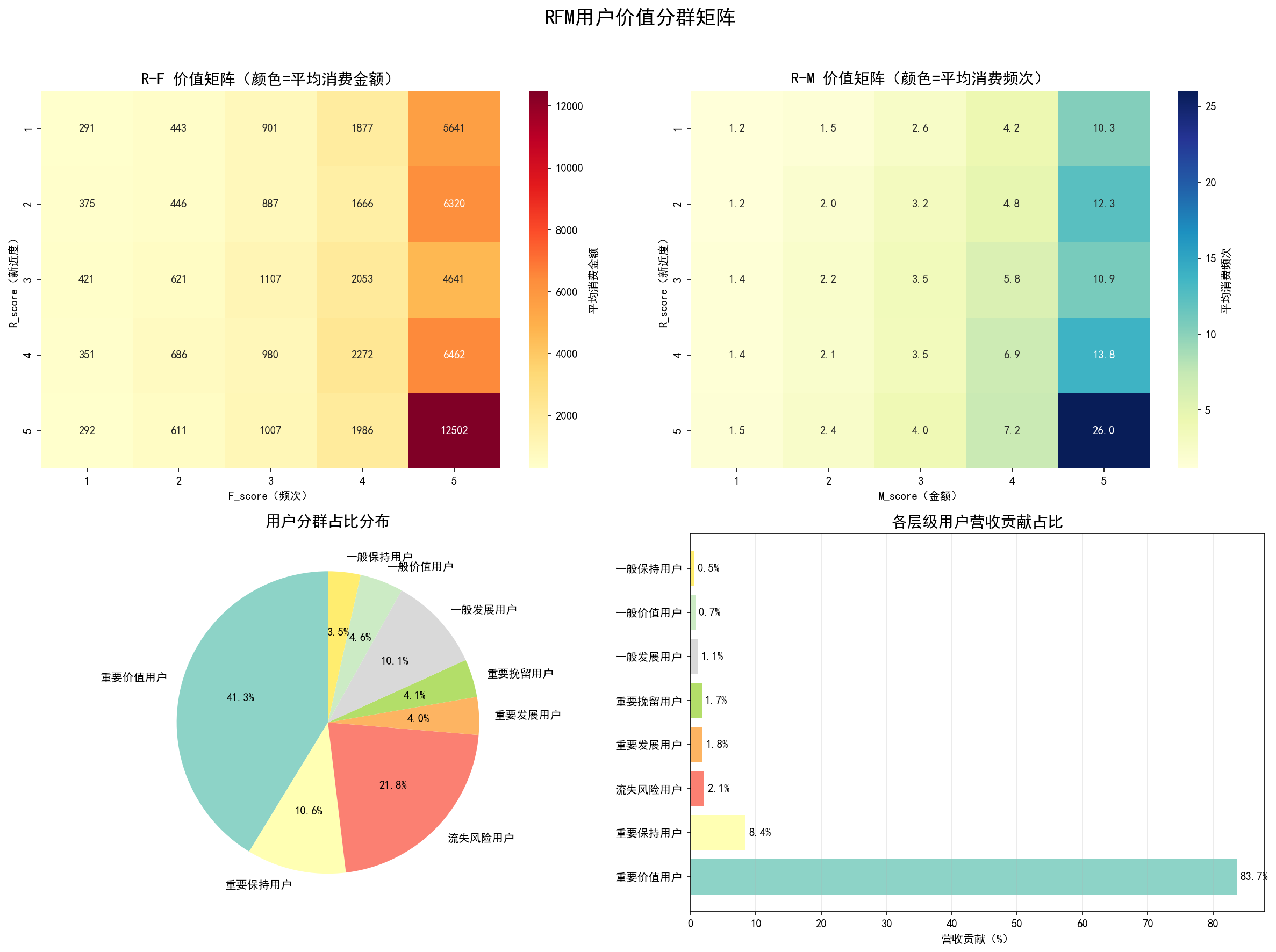
5.2 RFM 八分群详细统计
| 用户层级 | 用户占比 | 营收贡献 | 平均消费金额 | 平均购买频次 | 平均最近消费天数 |
|---|---|---|---|---|---|
| 重要价值用户 | 41.3% | 83.7% | £7,047 | 11.5 笔 | 28 天 |
| 重要保持用户 | 10.6% | 8.4% | £2,228 | 5.2 笔 | 89 天 |
| 流失风险用户 | 21.8% | 2.1% | £299 | 1.8 笔 | 142 天 |
| 重要发展用户 | 4.0% | 1.8% | £1,262 | 2.0 笔 | 35 天 |
| 重要挽留用户 | 4.1% | 1.7% | £1,156 | 1.9 笔 | 128 天 |
| 一般价值用户 | 5.4% | 1.0% | £537 | 4.5 笔 | 32 天 |
| 一般发展用户 | 5.4% | 0.6% | £304 | 1.6 笔 | 38 天 |
| 一般保持用户 | 7.4% | 0.7% | £323 | 3.1 笔 | 96 天 |
5.3 关键洞察
-
头部效应极其显著:前 51.9% 的用户(重要价值 + 重要保持)贡献了 92.1% 的营收。这完全符合电商行业的"二八定律",资源必须向 VIP 倾斜。
-
流失风险用户占比高:21.8% 的用户处于流失风险状态,但仅贡献 2.1% 营收。这意味着召回成本需要精打细算,不能盲目投入。
-
重要发展用户是增长引擎:4.0% 的用户消费金额高但频次低,是提升复购率的关键突破口。通过会员积分、订阅制等手段将其转化为重要价值用户,是提升 GMV 的最快路径。
-
复购率健康但仍有空间:72.35% 的复购率说明产品质量与用户满意度较高,但仍有 27.65% 的用户为一次性购买,需优化首单体验与二次触达。
六、可视化看板
本项目输出了 4 张核心可视化图表,直观呈现分析结果。
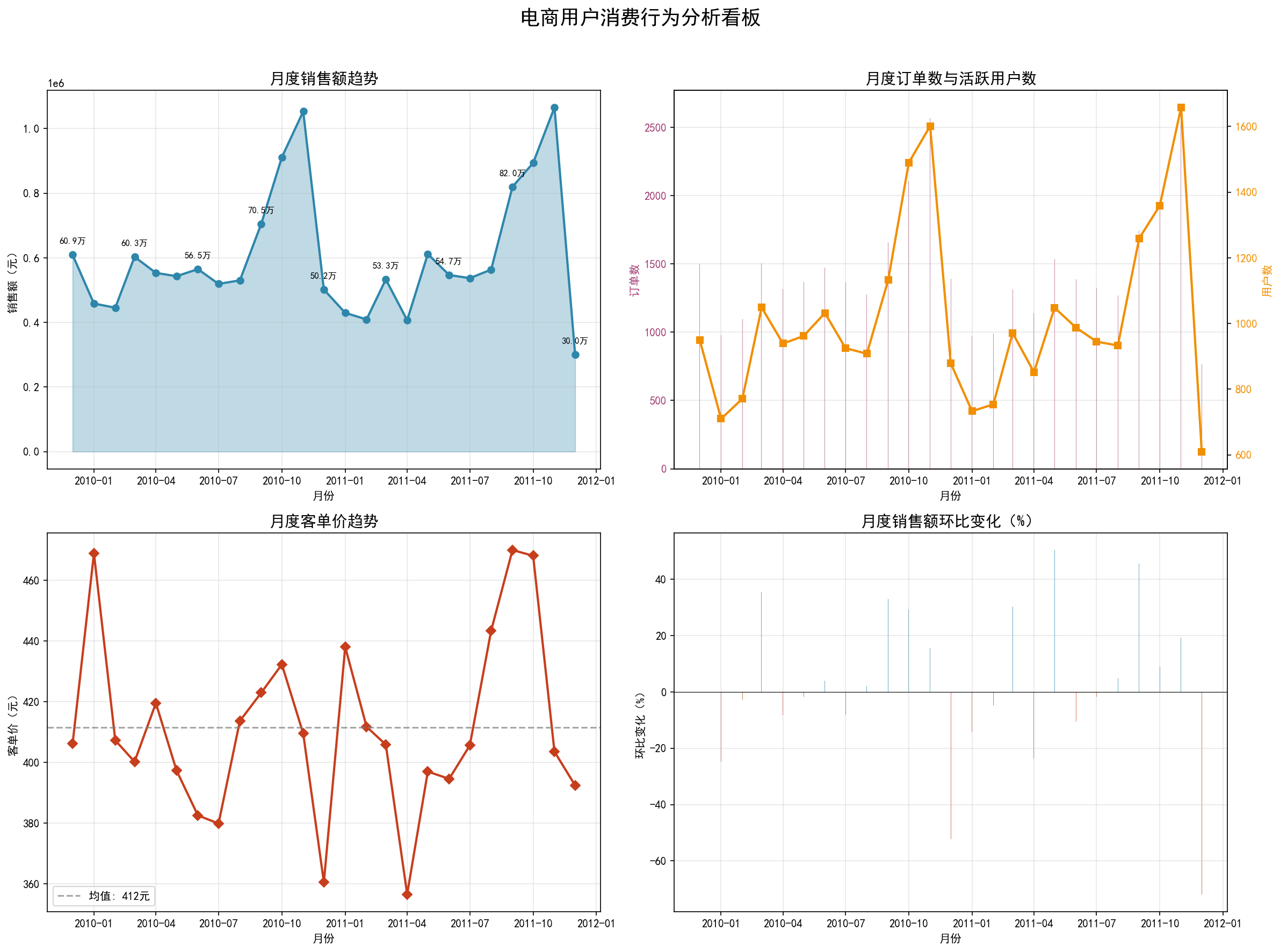
6.1 消费趋势时序图
展示分析期内月度销售额、订单数、用户数的变化趋势,识别销售高峰与低谷。从图中可以清晰看到 11-12 月的季节性销售高峰(圣诞礼品需求驱动),以及 1-2 月的传统淡季。
6.2 RFM 用户价值矩阵
以 R(最近消费)为横轴、F(消费频次)为纵轴、气泡大小表示 M(消费金额),直观展示用户分布与分层。从矩阵中可以清晰看到"重要价值用户"聚集在左上方(R 小、F 高),而"流失风险用户"分布在右下方。
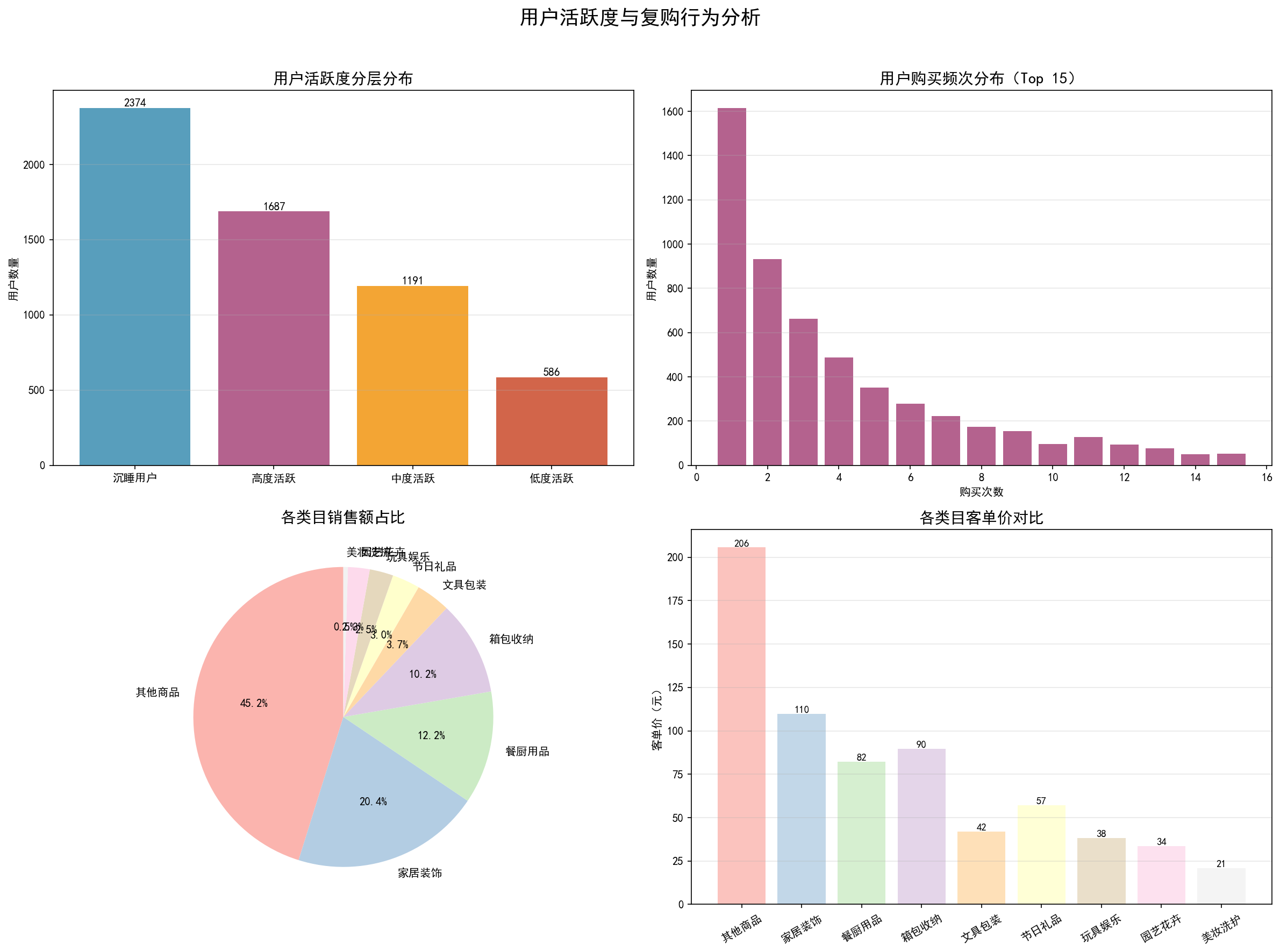
6.3 活跃度与复购分析
展示不同活跃度等级用户的复购率与客单价对比,验证活跃度与消费能力的正相关性。高活跃用户的客单价显著高于低活跃和沉睡用户。
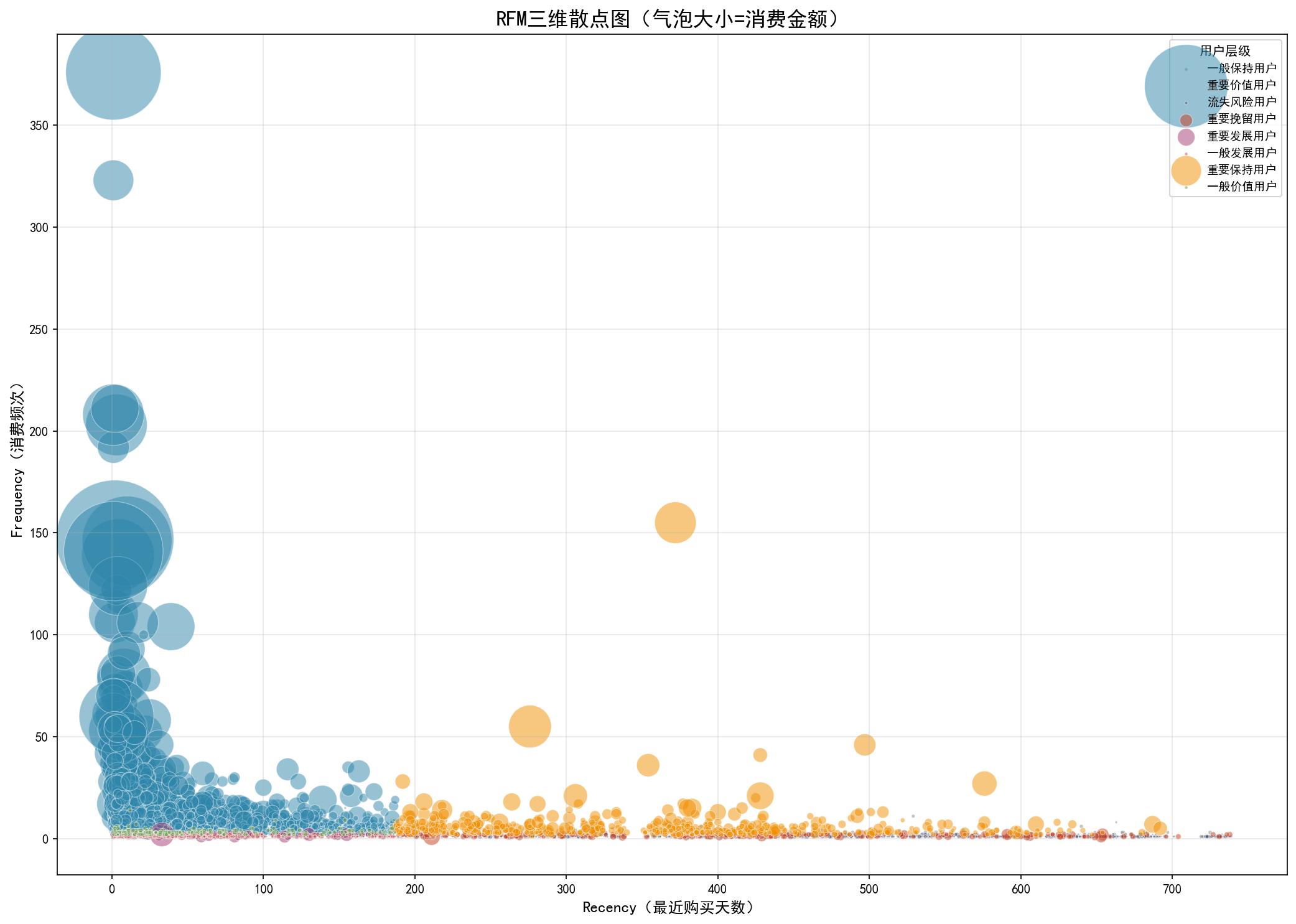
6.4 RFM 三维散点图
在三维空间中展示 R、F、M 三个维度的分布,颜色区分用户层级,直观感受用户价值的立体分布。高价值用户在三维空间中形成明显的聚集簇。
七、运营策略建议
基于 RFM 八分群结果,针对不同层级用户制定差异化运营策略:
7.1 重要价值用户(占比 41.3%,贡献 83.7% 营收)
- 策略:VIP 专属服务,提升忠诚度,防止流失
- 具体动作:
- 建立 VIP 会员体系,提供专属折扣、优先发货、生日礼品
- 定期推送新品预览与限量款,满足其尝鲜需求
- 一对一客户经理跟进,及时解决售后问题
- 邀请加入品牌社群,增强归属感
7.2 重要保持用户(占比 10.6%,贡献 8.4% 营收)
- 策略:召回激活,唤醒沉睡的高价值用户
- 具体动作:
- 发送个性化召回邮件/短信,附带大额优惠券(如满 £100 减 £20)
- 推送其历史购买品类的热销新品,降低决策成本
- 限时活动倒计时,制造紧迫感
7.3 流失风险用户(占比 21.8%,贡献 2.1% 营收)
- 策略:低成本召回,评估是否值得投入
- 具体动作:
- 发送"我们想念你"系列邮件,附带小额优惠券
- 推送清仓折扣与包邮活动,降低尝试门槛
- 对长期无响应用户停止投入,避免沉没成本
7.4 重要发展用户(占比 4.0%,贡献 1.8% 营收)
- 策略:提升购买频次,培养消费习惯
- 具体动作:
- 设计"满 N 单返券"活动,激励多次下单
- 推送搭配购、组合装,提升单次订单价值
- 订阅制服务(如每月礼盒),锁定长期复购
7.5 重要挽留用户(占比 4.1%,贡献 1.7% 营收)
- 策略:紧急挽留,防止彻底流失
- 具体动作:
- 电话/短信一对一沟通,了解流失原因
- 提供定制化解决方案(如退换货政策放宽)
- 赠送高价值礼品,重建品牌好感
八、项目复盘与反思
8.1 做得好的地方
- 数据清洗策略合理:采用 IQR 法而非 3σ 原则处理偏态分布的异常值,保留了更多有效数据
- 多数据集验证:使用三套同源数据集进行交叉验证,确保分析结果的稳定性
- 可复用的代码结构:将数据加载、清洗、分析、可视化模块化,支持单数据集和批量分析两种模式
8.2 可以改进的地方
- 时间序列预测:当前分析停留在描述性统计层面,下一步可以引入 ARIMA 或 Prophet 进行销售额预测
- 用户生命周期模型:RFM 是静态快照,结合 cohort 分析可以观察用户随时间的迁移路径
- 自动化部署:当前需要手动运行脚本,可以封装为定时任务或 Web 服务
8.3 最核心的收获
这个项目让我深刻体会到:数据分析的终点不是图表,而是可落地的业务决策。RFM 模型虽然经典,但结合五分位法和具体的运营策略后,才能真正产生价值。当运营同学拿到那份 Excel 报表,知道"这 41.3% 的重要价值用户应该发什么券、那 21.8% 的流失风险用户应该什么时候召回"时,数据分析才算完成了它的使命。
参考与致谢
- UCI Machine Learning Repository - Online Retail
- 阿里云天池 - Online Retail 数据集
- Kaggle - Online Retail II UCI
- Chen, D. (2019). RFM Model for Customer Segmentation. Medium.
项目已开源:ecommerce-rfm-analysis,欢迎 Star 和交流讨论。